Veo 3.0 は「映画級の映像制作・コンセプト可視化」のシーンで使えるか?


Google DeepMindが開発した最新の動画生成モデル「Veo 3.0」は、これまでのAI動画生成の課題であった「物理的な整合性」と「映像の解像度」を大きく向上させ、映画制作やハイエンドな広告制作の現場での実用性を視野に入れたモデルです。特に**「映画級の映像制作・コンセプト可視化」**という高度な要求が伴うシーンにおいて、その真価を発揮します。
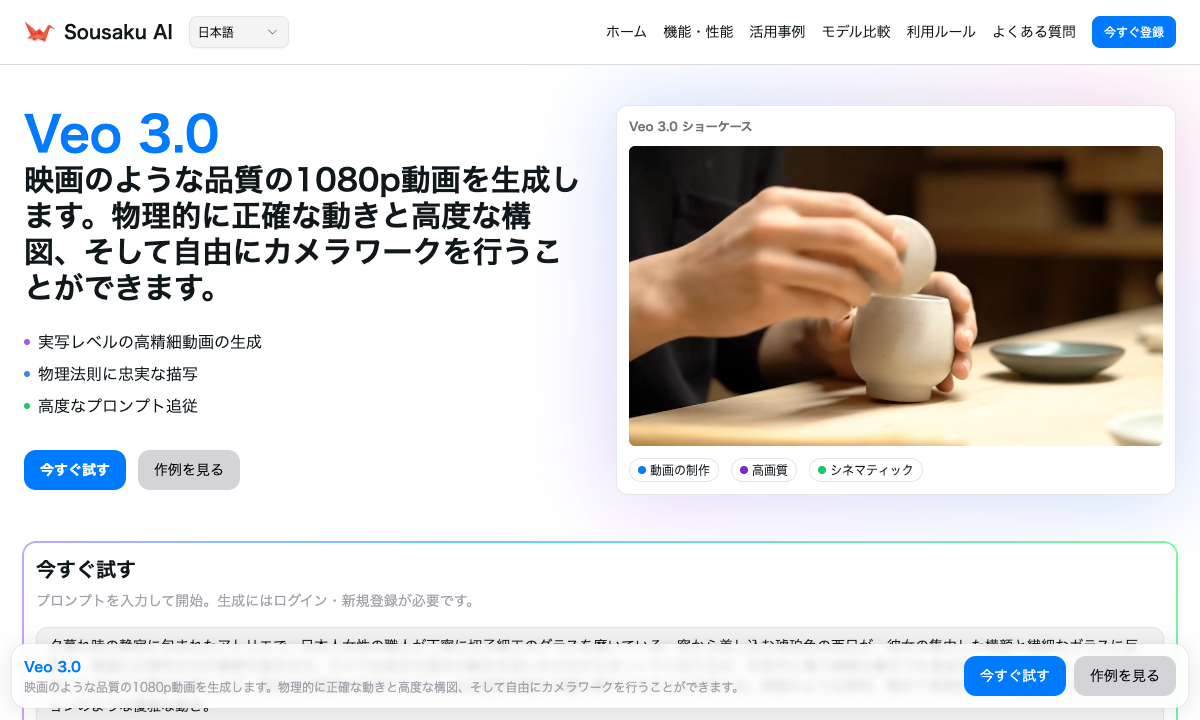
Veo 3.0は、自然言語のプロンプトから最大1080p以上の高解像度で、4〜8秒の整合性の取れた動画を生成可能です。Sousaku.AIのような統合プラットフォームを通じて利用することで、クリエイターは複数の高価な機材やレンダリング時間を費やすことなく、頭の中にあるイメージを即座に視覚化し、プロジェクトの初期段階における意思決定を加速させることができます。
「映画級の映像制作・コンセプト可視化」シーンの核心的な制作ニーズ
プロフェッショナルな映像制作や、クライアントワークにおけるコンセプト可視化(ビデオコンテ、Vコン)の現場では、単に「画像が動いている」だけでは不十分です。このシーンでは、以下の要素が不可欠となります。
- 物理法則の再現とリアリティ: 流体、光の反射、人物の動作などが、違和感なく現実世界に即していること。
- 高い解像度と画質: プレゼンテーションやテスト試写に耐えうる、1080p以上のクリアな画質。
- 演出意図(レンズ言語)の反映: ドリー、パン、ズーム、被写界深度(ボケ量)など、撮影用語を用いた指示が正確に反映されること。
- 一貫性: シーン内でのキャラクターやオブジェクトが破綻せず、数秒間維持されること。
これらの要素は、制作準備段階(プリプロダクション)におけるイメージの共有や、本番撮影前のシミュレーションにおいて、手戻りを防ぐための重要な品質基準となります。
Veo 3.0 を使用して「映画級の映像制作・コンセプト可視化」を行うメリット
Veo 3.0は、上記の厳しいプロのニーズに対して、いくつかの明確なアドバンテージを持っています。Sousaku.AIなどのプラットフォームでこのモデルを選択する主な理由は以下の通りです。
1. 高度なプロンプト理解とレンズ言語の再現
Veo 3.0の最大の特徴は、テキストによる指示(プロンプト)への追従性が極めて高い点です。「映画的な照明(Cinematic lighting)」や「ドローン撮影(Drone shot)」といった抽象的な指示だけでなく、具体的なカメラワークの指示を正確に解釈します。これにより、監督やアートディレクターが意図する「画作り」をAI上で再現しやすくなっています。
2. 物理演算のようなリアルな挙動
従来の動画生成AIでは苦手とされていた、複雑な動き(水しぶき、爆発、布の揺れなど)の表現力が向上しています。Veo 3.0は物理的な整合性を重視して設計されているため、実写合成用の素材や、VFXのラフ制作としても実用的なレベルに達しつつあります。
3. テキストおよび画像からの柔軟な生成
テキストから動画生成(Text-to-Video)だけでなく、既存のコンセプトアートや写真をベースにした画像から動画生成(Image-to-Video)にも対応しています。これにより、アートディレクターが描いた静止画のイメージボードをそのまま動かし、チーム全体で「動きのイメージ」を共有するといった使い方が可能です。
「映画級の映像制作・コンセプト可視化」における Veo 3.0 の典型的な活用例
ここでは、実際の制作フローを想定したVeo 3.0の具体的な使用例を紹介します。
ケース1:CM制作におけるシネマティックな商品カット(Text-to-Video)
高級車のCMや飲料メーカーの広告など、商品の魅力を最大限に引き出すための「シズル感」のあるカットを作成します。実写撮影前のライティングや構図の検証(アングルチェック)として非常に有効です。
プロンプト例:
A cinematic close-up shot of a luxury sports car driving through a neon-lit city street at night during rain. Raindrops hitting the hood, reflections of neon lights on the wet asphalt. 4k resolution, high detail, photorealistic, slow motion.

このプロセスは、テキストから動画生成(Text-to-Video)機能を使用して行います。
ケース2:ファンタジー映画の環境コンセプト動画化(Image-to-Video)
映画やゲームの背景美術として描かれたコンセプトアート(静止画)を元に、カメラを動かして空間の広がりや雰囲気をプレゼンテーションします。静止画では伝わりにくい「没入感」を演出できます。
プロンプト例:
Drone camera panning slowly forward over the mystical ancient ruins, volumetric fog, sun rays piercing through the clouds, birds flying in the distance, cinematic atmosphere.

このプロセスは、手持ちの画像素材をアップロードし、画像から動画生成(Image-to-Video)機能を使用して行います。
このシーンで Veo 3.0 を使用する際の注意点
Veo 3.0は強力なツールですが、プロフェッショナルな現場で使用する際にはいくつかの制限や注意点を理解しておく必要があります。
- 音声生成の不在: 現行のVeo 3.0は映像生成に特化しており、音声やBGMは生成されません(次世代のVeo 3.1で実装予定)。そのため、完パケ(完成品)を作るには別途音響編集が必要です。
- 生成時間の長さ(尺): 一度に生成できるのは通常4〜8秒の短いクリップです。長尺の映像を作る場合は、複数のカットを生成して編集ソフトで繋ぐ必要があります。
- 試行回数(ガチャ要素): 物理表現は優秀ですが、常に100%意図通りの動きをするわけではありません。特に複雑なアクションシーンでは、理想のテイクが出るまで何度か生成を繰り返す必要があります。
- テキスト描写の限界: 映像内の看板やモニターに表示される微細な文字情報の正確性は、まだ発展途上です。
どのようなユーザーが「映画級の映像制作・コンセプト可視化」で Veo 3.0 を使うべきか
このモデルは、以下のようなユーザーにとって、業務効率を劇的に改善する可能性があります。
- 映像ディレクター・演出家: 絵コンテの段階で、クライアントやスタッフと具体的な「動き」のイメージを共有したい方。
- 広告代理店のクリエイティブ: 企画提案(ピッチ)の際に、静止画の資料ではなく、インパクトのある動画資料でプレゼンを行いたい方。
- VFX・CGアーティスト: 3Dでモデリングする前のラフ案として、シミュレーションやルックデヴ(LookDev)の方向性を探りたい方。
- インディーズ映画制作者: 低予算で高品質な視覚効果(Bロール素材など)を作品に取り入れたい方。
Sousaku.AI で「映画級の映像制作・コンセプト可視化」関連の創作を始める方法
Sousaku.AIでは、Google DeepMindのVeo 3.0を含む世界中のトップクラスのAIモデルを、一つのプラットフォームで利用可能です。
映像制作の現場では、Veo 3.0だけでなく、他の動画生成モデル(KlingやLumaなど)と比較検討したい場面も多々あります。Sousaku.AIのモデル比較機能を使えば、同じプロンプトで異なるモデルの出力結果を並べて確認できるため、プロジェクトのトーンに最適なモデルを即座に見つけることができます。
また、モデル一覧から、用途に合わせて最適なツールを選択し、ポイント消費型のシステムで無駄なく制作を進めることが可能です。
まとめ:Veo 3.0 はあなたの「映画級の映像制作・コンセプト可視化」ニーズに適しているか?
Veo 3.0は、現時点での動画生成AIにおいて「リアリティ」と「指示への忠実度」のバランスが最も取れたモデルの一つです。特に、**「実写に近い高品質な素材が欲しい」「カメラワークにこだわりたい」**というニーズに対しては、極めて高い適性を持っています。
一方で、長時間のストーリー動画を一本の生成で完結させたい場合や、音声まで含めた生成を望む場合は、他のツールとの併用や編集作業が必須となります。しかし、プロフェッショナルな映像制作の「素材作り」や「アイデア出し」のパートナーとして、Veo 3.0は強力な武器となるでしょう。
まずはご自身の目で、その映像美と物理表現の進化を確かめてみてください。
- 公式サイトへアクセス: https://sousaku.ai
- Veo 3.0 の詳細を見る: https://sousaku.ai/models/google-video-veo-3.0
- 登録して創作を始める: https://sousaku.ai/signin




